My next question was whether he spent some time optimizing the data layout as well. The answer was surprising. In response, I got some O(n*m) formulas and abstract run time estimations, potentially filling an entire textbook, but nothing on the actual arrangement of data related to the question. I realized that even seasoned experts are not always fully aware of the importance of in-memory data structure. Especially strange is how we can overlook its huge impact while giving so much respect to other constant factors like a few percent extra CPU speed.
Long story short, organizing and accessing your data along proper patterns makes your code run faster. Let’s find out how much faster.
The experiments presented here are intentionally kept simple. Their sole purpose is to give a hint on the order of magnitude of the gain these simple techniques cause in execution times. For the sake of brevity, the measured code simply reads from memory—like read-intensive applications—in a loop.
Deep understanding of memory management, cache architectures, and data prefetching strategy is out of the scope of this post and not my main field either; still, even a few lines of code can demonstrate how large an impact memory access patterns have on run times.
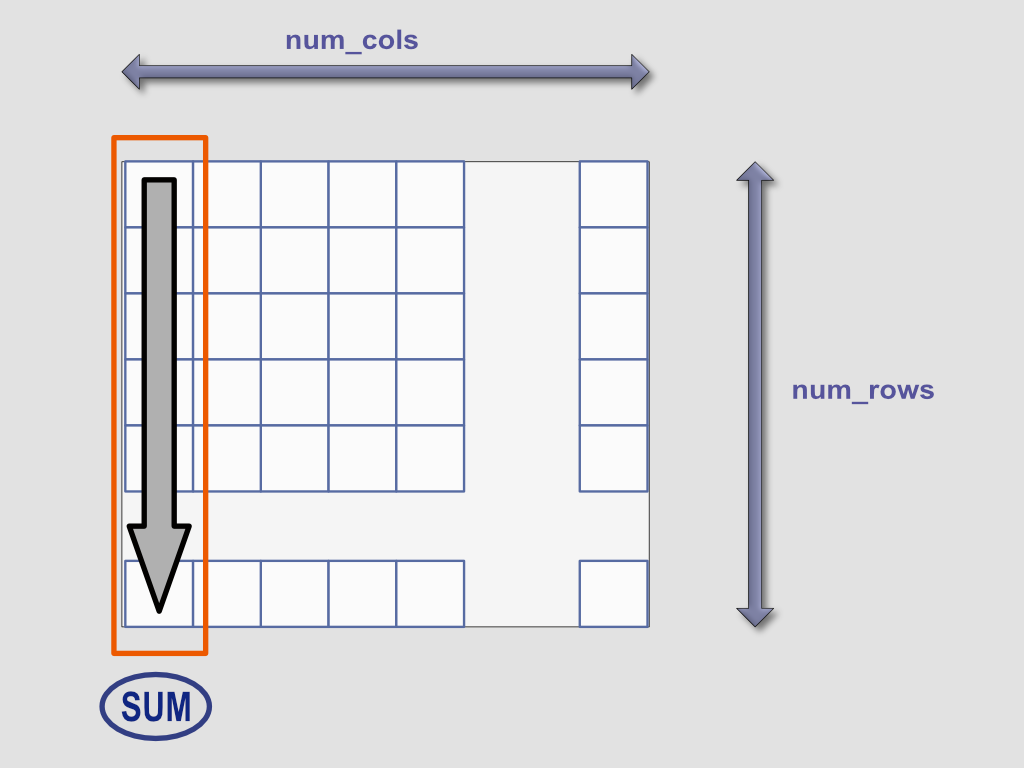
The test codes are different from Sutter’s example. We do not even randomize the memory traversal but keep accessing the data in increasing order with equidistant steps; we only simulate those data elements belonging together and not stored in an optimal, compact way.
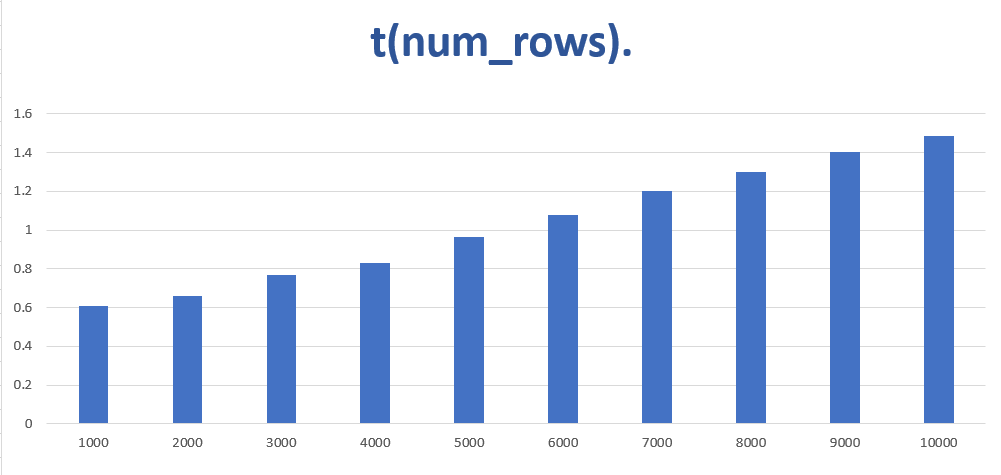
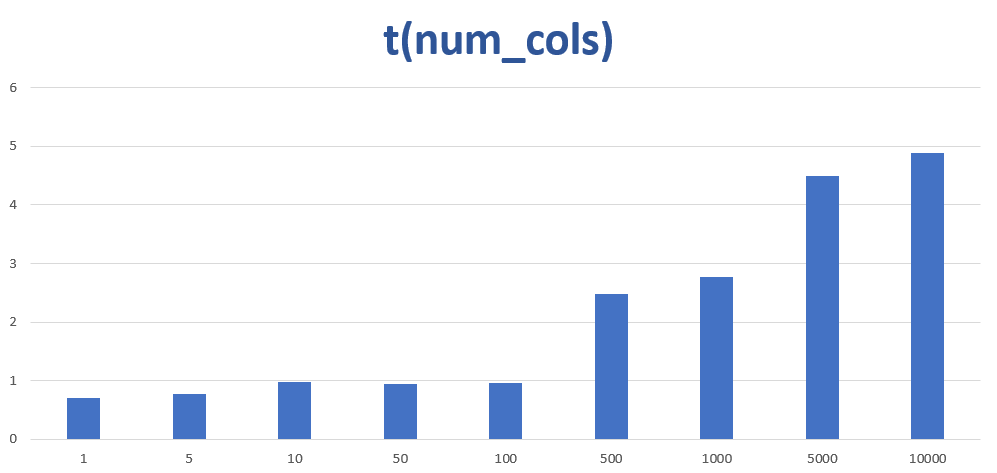
We allocate a great chunk of memory that we access sequentially, but increase the step sizes after each experiment. Increasing step sizes makes cache misses more frequent and gives the prefetcher a run for its money. Note, in each experiment, we do exactly the same number of reads; the only difference is _where_ we read from.
To allow really big step sizes, we treat the buffer in a circular way. (The buffer’s size is chosen to be a power of two. Achieving circular access with the modulo operator “%” had some measurable overhead over simply masking with the “&” operator in the core loop’s execution time. However, the difference gets negligible at bigger step sizes, so feel free to go with the modulo if you want an even shorter code without the initial binary sorcery.) Step sizes being close to the half, third, etc. of the buffer size should not be chosen because within two or three steps you get back to the same memory region.
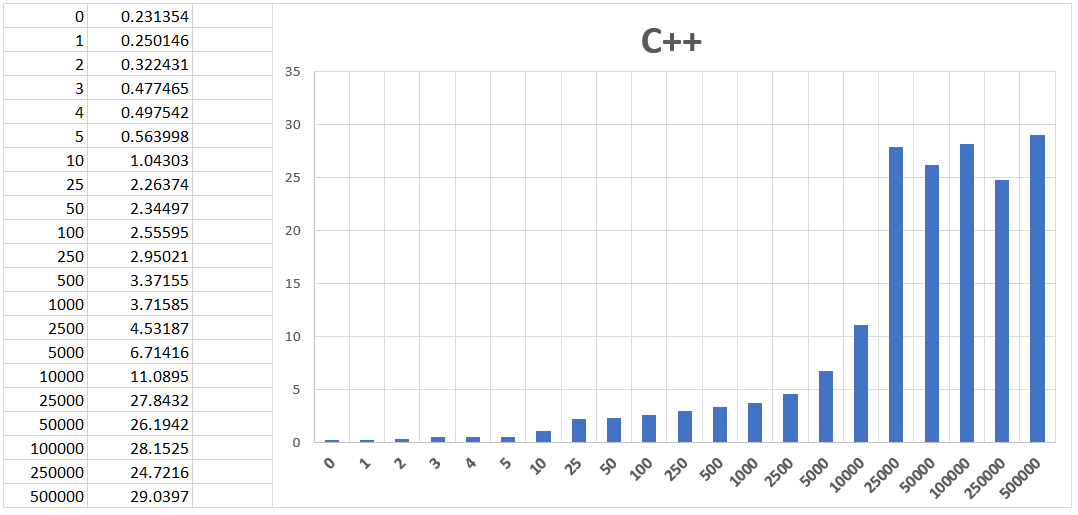
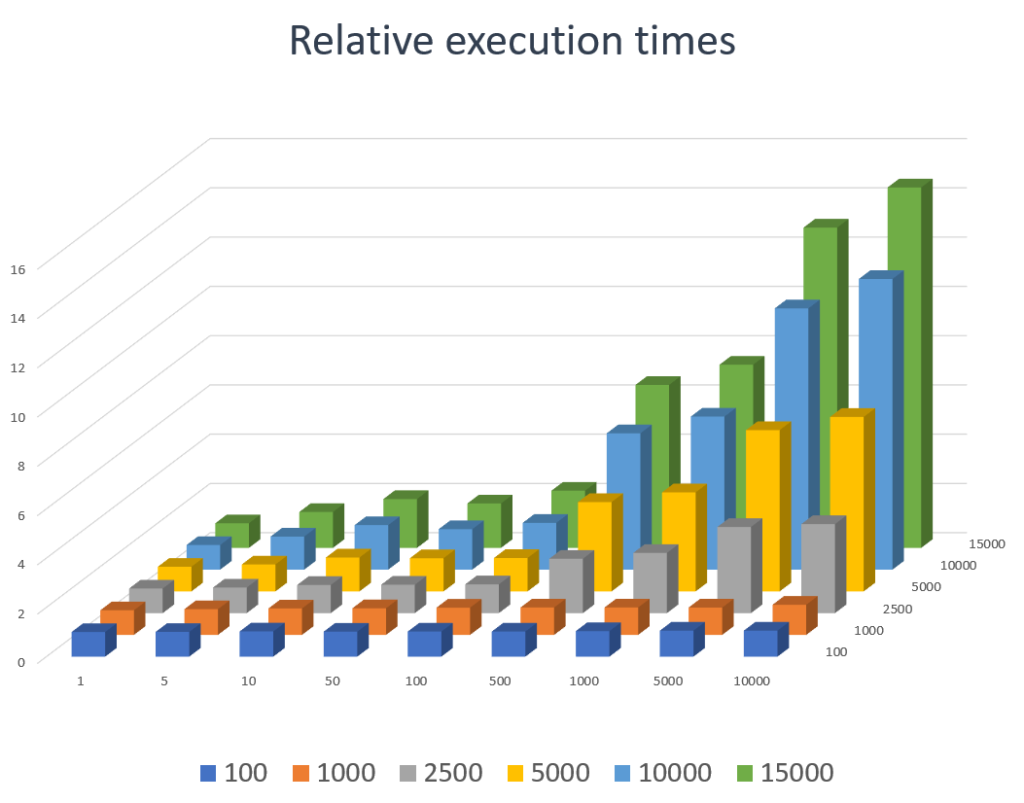
Bottom line up front: Compared with the optimal access pattern, the worst case took longer by some two orders of magnitude in both languages.
The measured times are remarkably similar for each step size between languages. (The C# baseline case (step size = 1) had a bit longer run time than its C++ counterpart. That makes the ratio against the worst cases a bit different. Otherwise, the results go hand in hand.) The ratio was 116 for the C++ code and 73 for C#.
The cases with step size = 0 are given for reference as they represent the case where we always read a single location, i.e., the value is guaranteed to come from cache after the first access. As we see, the cases with step size = 1 take barely longer. The prefetcher probably knows its job.
The measurements start steeply increasing soon, however. By the time we reach the step size of 25, the execution times are already 10x times longer (or 3–4x for step size of 10). This is not even an unrealistic case, we do it every day: just enumerate one selected field from an array of bigger structs.
The situation gets worse when moving to even bigger steps as we bring in further multipliers. Although it’s less likely that you have such massive structs in an array, allocations from a fragmented heap in long running server applications or write-intensive use cases of chained lists can easily make us access unrelated distant regions in a simple traversal.